
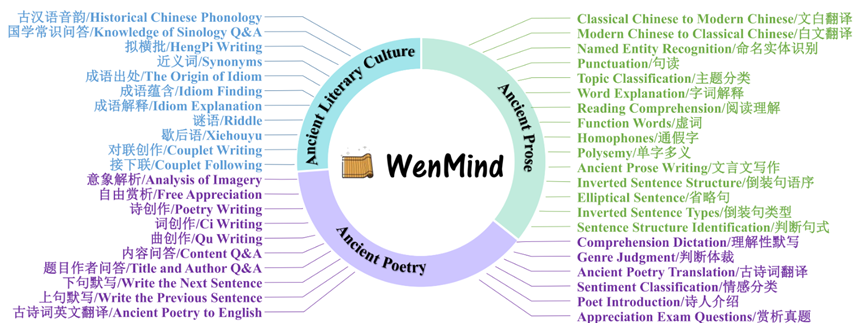
WenMind 是一个综合性基准测试,专门用于评估中国古典文学和语言艺术 (CCLLA) 中的大型语言模型 (LLM)。WenMind 涵盖古代散文、古代诗歌和古代文学文化的子领域,包括 4875 个问答对,跨越 42 个细粒度任务(如图 1 所示),3 种问题格式(填空题、多项选择题和问答题),以及 2 个评价场景(领域导向和能力导向)。
数据格式:
{
“id”: 2464,
“domain”: “ancient literary culture”,
“capability”: “knowledge”,
“question_format”: “QA”,
“coarse_grained_task_zh”: “成语”,
“coarse_grained_task_en”: “idiom”,
“fine_grained_task_zh”: “成语解释”,
“fine_grained_task_en”: “idiom explanation”,
“question”: “解释下面成语的意思:\n暮去朝来”,
“answer”: “黄昏过去,清晨又到来。形容时光流逝。”
}
以下是对数据示例中各个字段的说明:
- id:数据样本的唯一标识符,用于区分不同的样本。
- domain:数据样本所属的领域,包括古代散文、古代诗歌和古代文学文化。
- capability:数据样本的能力类型,包括 knowledge、understanding 和 generation。
- question_format:问题的格式,表示样本中的问题类型,包括 FB、MCQ 和 QA。
- coarse_grained_task_zh:粗粒度任务分类的中文名称。描述样本的粗粒度任务类别,共 26 个类别。
- coarse_grained_task_en:粗粒度任务分类的英文名称。对应 coarse_grained_task_zh,描述样本的粗粒度任务类别,一共 26 个类别。
- fine_grained_task_zh:细粒度任务分类的中文名称。描述样例的细化任务类别,共 42 个类别。
- fine_grained_task_en:细化任务分类的英文名称。对应 fine_grained_task_zh,描述样本的细粒度任务类别,一共 42 个类别。
- question:问题的实际内容。要在示例中回答的问题。
- answer:对应问题的答案。提供对问题的详细回答。
任务列表
T1-1: 倒装句语序
- 任务描述:正确倒置句子的词序。
- 能力:理解
- 比例尺:18
T1-2: 省略句
- 任务描述:回答省略的句子中遗漏的信息。
- 能力:理解
- 比例尺:32
T1-3: 倒装句类型
- 任务描述:识别倒置句子的倒置类型。
- 能力:理解
- 比例尺:7
T1-4: 判断句式
- 任务描述:确定句子的语法类型。
- 能力:理解
- 比例尺:43
T2: 文白翻译
- 任务描述:将文言文翻译成现代汉语。
- 能力:理解
- 比例尺:200
T3: Modern Chinese to Classical Chinese (白文翻译)
- 任务描述:将现代汉语翻译成文言文。
- 能力:理解
- 比例尺:200
T4: Named Entity Recognition (命名实体识别)
- 任务描述:从文言文语句子中提取命名实体。
- 能力:理解
- 比例尺:200
T5:标点符号 (句读)
- 任务描述:为文言文语句子添加标点符号。
- 能力:理解
- 比例尺:200
T6: Topic Classification (主题分类)
- 任务描述:根据 文言文语句 选择主题类别。
- 能力:理解
- 比例尺:200
T7: Word Explanation (字词解释)
- 任务描述:解释文言文中词中的单词和短语。
- 能力:理解
- 比例尺:100
T8: Reading Comprehension (阅读理解)
- 任务描述:阅读中国古典文本并回答相关问题。
- 能力:理解
- 比例尺:100
T9: 虚词
- 任务描述:回答中国古典语句子中虚词的用法。
- 能力:理解
- 比例尺:100
T10: 同音字 (通假字)
- 任务描述:确定字符是否为同音字。
- 能力:理解
- 比例尺:200
T11: Polysemy (单字多义)
- 任务描述:区分同一字符的不同含义。
- 能力:理解
- 比例尺:200
T12: 文言文写作
- 任务描述:用文言文写作。
- 功能:生成
- 比例尺:100
T13-1: 赏析真题
- 任务描述: 回答基于古代诗歌的鉴赏问题。
- 能力:理解
- 比例尺:150
T13-2: Free Appreciation (免费赏析)
- 任务描述: 对古代诗歌进行免费而详细的分析。
- 能力:理解
- 比例尺:100
T14-1: 诗歌创作
- 任务描述:根据主题创作一首诗。
- 功能:生成
- 比例尺:30
T14-2: 词创作
- 任务说明:根据主题编写 ci。
- 功能:生成
- 比例尺:50
T14-3: 曲创作
- 任务说明:根据主题编写 qu。
- Capability: Generation
- Scale: 20
T15-1: Content Q&A (内容问答)
- Task Description: Answer the complete content of ancient poetry according to the title and author.
- Capability: Knowledge
- Scale: 200
T15-2: Title and Author Q&A (题目作者问答)
- Task Description: Answer the title and author according to the content of ancient poetry.
- Capability: Knowledge
- Scale: 200
T15-3: Write the Next Sentence (下句默写)
- Task Description: Write the next sentence according to the previous sentence in the ancient poem.
- Capability: Knowledge
- Scale: 100
T15-4: Write the Previous Sentence (上句默写)
- Task Description: Write the previous sentence according to the next sentence in the ancient poem.
- Capability: Knowledge
- Scale: 100
T15-5: Comprehension Dictation (理解性默写)
- Task Description: Provide ancient poetry sentences that meet the requirements.
- Capability: Knowledge
- Scale: 30
T15-6: Genre Judgment (判断体裁)
- Task Description: Judge the genre of ancient poetry.
- Capability: Knowledge
- Scale: 120
T16: Ancient Poetry Translation (古诗词翻译)
- Task Description: Translate ancient poetry into modern Chinese.
- Capability: Understanding
- Scale: 200
T17: Sentiment Classification (情感分类)
- Task Description: Judge the sentiment contained in ancient poetry.
- Capability: Understanding
- Scale: 200
T18: Ancient Poetry to English (古诗词英文翻译)
- Task Description: Translate ancient poetry into English.
- Capability: Understanding
- Scale: 50
T19: Poet Introduction (诗人介绍)
- Task Description: Provide a detailed introduction of the poet.
- Capability: Knowledge
- Scale: 110
T20: Analysis of Imagery (意象解析)
- Task Description: Provide the meanings of the imagery.
- Capability: Knowledge
- Scale: 185
T21-1: Couplet Following (接下联)
- Task Description: Create the following couplet based on the previous one.
- Capability: Generation
- Scale: 100
T21-2: Couplet Writing (主题创作)
- Task Description: Write a couplet based on the theme.
- Capability: Generation
- Scale: 100
T21-3: HengPi Writing (拟横批)
- Task Description: Write HengPi based on the content of a couplet.
- Capability: Generation
- Scale: 100
T22-1: Synonyms (近义词)
- Task Description: Provide the synonym for the idiom.
- Capability: Knowledge
- Scale: 100
T22-2: The Origin of Idiom (成语出处)
- Task Description: Provide the source of the idiom.
- Capability: Knowledge
- Scale: 100
T22-3: 成语找 (成语蕴含)
- 任务描述: 从中国古代句子中提取成语并提供其含义。
- 能力:知识
- 比例尺:100
T22-4: Idiom Explanation (解释含义)
- 任务描述:提供成语的含义。
- 能力:知识
- 比例尺:100
T23: Riddle (谜语)
- 任务描述:根据线索或巧妙的提示猜出答案。
- 能力:知识
- 比例尺:100
T24: 歇后语
- 任务描述:在前半部分的基础上完成谚语的后半部分。
- 能力:知识
- 比例尺:100
T25: 古汉语音韵
- 任务描述: 回答有关中国古代语音和韵律的问题。
- 能力:知识
- 比例尺:100
T26: 国学常识问答
- 任务描述:回答有关汉学的问题。
- 能力:知识
- 比例尺:130
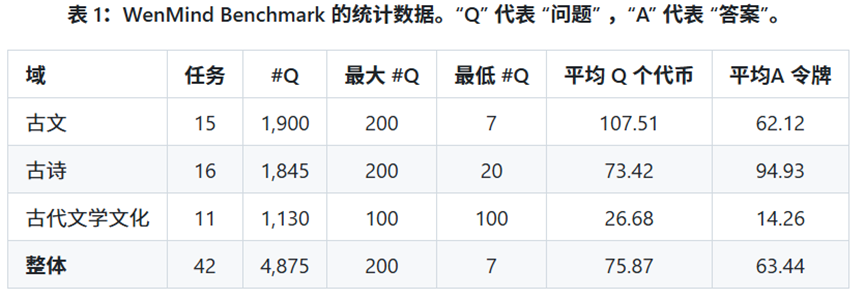
数据统计
开源模型
对于开源模型,我们在本地执行推理,只需要模型路径和输出文件路径即可获得答案。
–model_path The path to the model, defaults to loading from huggingface
–output_path The file path for the model’s answer output, defaults to {model_name}_result.json
例如
CUDA_VISIBLE_DEVICES=0,1 python Evaluation_Code/Inference/Test_Baichuan2-7B-Chat.py \
–model_path baichuan-inc/Baichuan2-7B-Chat \
–output_path Baichuan2-7B-Chat_result.json
API 模型
对于 GPT-3.5 和 GPT-4 模型,请提供两个参数:和 。
对于 ERNIE-3.5 和 ERNIE-4.0 模型,请提供两个参数:和 。
对于 Spark 模型,请提供三个参数:、 和 。
有关详细信息,请参阅每个 API 模型的官方文档。api_base api_key api_key secret_key api_key secret_keyappid
例如
python Test_ERNIE-3.5-8K-0329.py \
–API_KEY {api_key} \
–SECRET_KEY {secret_key} \
–output_path {output_path}
b. 使用 ERNIE-3.5 对响应进行评分
步骤 1:检查 LLM 响应文件是否与文件格式一致。JSON/LLM_Response_Examples.json
步骤 2:打开文件,为评分模型 ERNIE-3.5 输入 and,替换为 LLM 响应文件的存储路径,替换为将保存评分结果的路径,替换为评分文件的存储路径。Evaluation_Code/LLM_Scoring.pyAPI_KEYSECRET_KEYLLM_response_pathLLM_score_pathLLM_prompt_pathJSON/Task_Score_Prompt.json
步骤 3:执行以下命令,获取评分结果。
python Evaluation_Code/LLM_Scoring.py
c. 计算模型的分数
步骤 1:检查评分文件是否与文件格式一致。JSON/LLM_Score_Examples.json
第 2 步:打开文件并替换为评分文件的存储路径。Evaluation_Code/Calculate_Score.pyLLM_score_path
步骤 3:执行以下命令以获取模型的分数。
python Evaluation_Code/Calculate_Score.py