
开发了TongGu,一个领先的垂直领域LLM,擅长管理广泛的CCU任务;
设计了一个从文言文文本自动生成指令数据的流水线,并构建了第一个公开的文言文指令数据集ACCN-INS;
提出了一种稀疏微调方法–冗余感知微调(RAT),以减轻两阶段微调中的灾难性遗忘; 为了减少LLM在知识密集型文言文任务中的幻觉,引入了一种特定于任务的高效检索增强生成(RAG)方法。
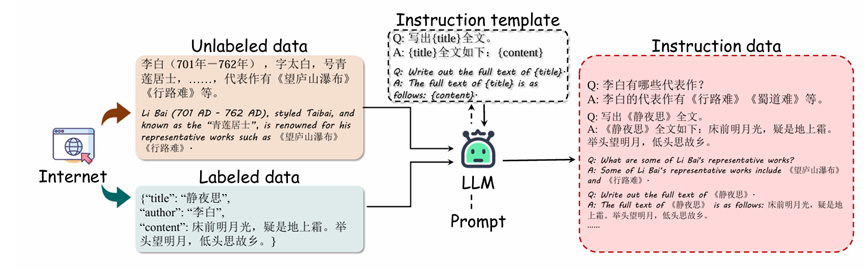
ACCN-INS数据集:文言文问答(QA)任务中人工标注的复杂性需要大量的人力专业知识,导致劳动高强度的过程。为了减轻劳动强度,利用LLM进行自动数据标注成为一种自然而高效的解决方案。然而,LLM在数据生成过程中存在无意中引入不准确性的倾向。为了解决这个问题,提出了一种半自动化的标注方法,该方法使用对齐的LLM结合文言语料库,从而为专门的CCU任务生成可靠的指导数据。
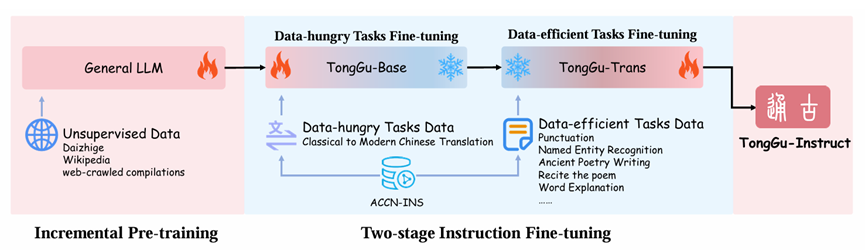
TongGu是专门为文言文理解(CCU)设计的通才LLM,其能力基于三个核心步骤构建,如图所示。首先,在由古典和现代汉语组成的46亿个tokens的混合语料库上对TongGu进行增量预训练,以丰富其CCU知识。其次,TongGu使用PEFT方法RedundancyAware Tuning(RAT)对数百万指令数据进行微调,不仅提高了多任务理解能力,而且确保了高效的指令调优。第三,我们介绍了CCU-RAG,一个特定于任务的检索增强生成(RAG)机制,以减轻幻觉在知识密集型任务。通过这三个步骤,TongGu证明了它能够有效地处理24个不同的CCU任务,使其成为理解文言文的强大工具。
预训练:对于TongGu的增量预训练,策划了由文言文和现代汉语文本组成的混合增量预训练数据,总共有24.1亿个标记(使用来自百川2 – 7 B-Base的标记器)
微调: 不同的CCU任务可以根据其数据需求分为数据饥饿型和数据高效型。前者需要大量的数据才能达到满意的效果,这一点在古今汉语的翻译任务中表现得尤为突出。然而,后者能够实现令人满意的性能与适度的数据规定,如标点符号恢复或主题分类。为了同时满足数据饥渴和数据高效的任务需求,进行了两阶段的微调过程,首先在具有大量数据的数据饥渴翻译任务上对TongGu进行微调,然后在具有较小规模数据的标点符号和主题分类等数据高效任务上对其进行微调。通过渐进式微调,该模型可以有效地利用大规模数据进行主要翻译任务,同时为具有有限数据的多个任务实现高效的迁移学习和专业化,从而培养全面的CCU任务熟练度。尽管两阶段微调在一般能力培养方面具有优势,但该方案潜在地面临灾难性遗忘问题。为了缓解这个问题,提出了一种新的PEFT方法,称为冗余感知调谐(RAT)。最近的研究已经揭示了LLM中的某些层是高度冗余的,这表明它们可以被删除而不会显著影响下游任务的性能。基于这一灵感,RAT识别并保留了这些冗余层,同时在新任务的训练过程中冻结了其他层。通过选择性地仅更新被认为对以前的任务不重要的冗余层,这种方法有效地保留了所获得的知识,从而减轻了因果遗忘,同时能够有效地适应新的任务。
算法1总结了RAT的过程。最初,随机选择一部分训练数据作为校准集,以提取和监控模型的内部动态。随后,在推理过程中收集来自每个模型层的隐藏状态表示,并串联计算I/O隐藏状态之间的余弦相似度。第i层的I/O隐藏状态之间的余弦相似度计算为:
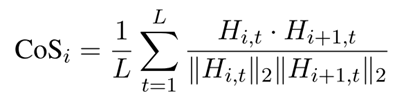
其中Hi,t表示层i在时间步t处的隐藏状态向量,||·||表示L2归一化,L表示样本句子长度。计算校准集中所有样本的余弦相似性的平均值。最后,冻结表现出较低相似性分数的层。由于更深层往往具有更大程度的冗余,已经实现了分组和排名策略,以避免仅对更深层进行微调而对模型的学习能力造成潜在损害。将TongGu地层按深度从浅到深分为N组。在每个组中,选择性地对表现出最高冗余度的层进行微调,而其余层则保持冻结。
最后,冻结表现出较低相似性分数的层。由于更深层往往具有更大程度的冗余,已经实现了分组和排名策略,以避免仅对更深层进行微调而对模型的学习能力造成潜在损害。将TongGu地层按深度从浅到深分为N组。在每个组中,选择性地对冗余度最高的层进行微调,而其余层则保持冻结。
接着使用ACCN-INS的数据有效任务数据对TongGu-7b-trans模型进行微调,将模型的能力培养到更广泛的CCU任务中。此外,还从ShareGPT(shareAI,2023)中筛选出了1万个人类与AI助手之间的对话样本作为补充数据,进一步增强了模型的对话能力。最后,得到了最终的模型–TongGu-7B-Instruct。为了解决训练过程中的灾难性遗忘问题,在两个阶段中使用了所提出的RAT方法,其中N被设置为8。在第一阶段中,增量预训练数据的子集用作校准集。在第二阶段,使用了一个古典到现代汉语翻译语料库的子集来实现同样的目的。更多详细信息请参见附录B。4.3CCU-RAG在知识密集型CCU任务中,一般用途的LLM和在该领域的初步努力通常会遭受严重的幻觉。最近,检索增强生成(RAG)已被证明是减轻LLM中的这些幻觉的有效解决方案(Gao等人,2023;Zhao等人,2024年)的报告。因此,提出CCURAG,一个针对特定任务的高效RAG框架,以提高从TongGu生成的输出的准确性和可靠性。
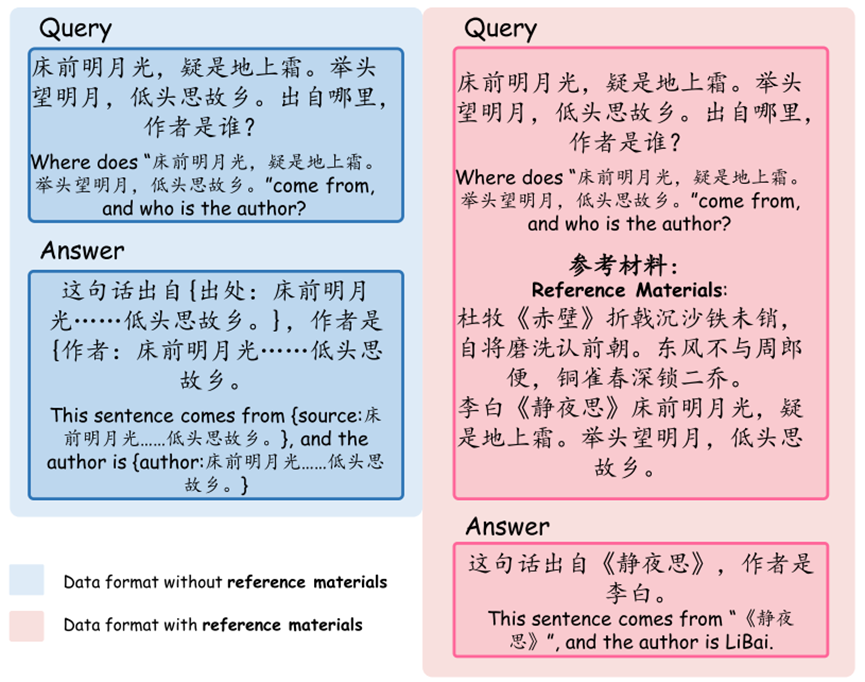
首先,从教学数据中提取知识密集型样本,包括来源检索、作者检索、前句背诵、下句背诵、整首诗背诵。随后,这些样本被重新格式化为两种类型的数据,以模拟RAG中的两个步骤。一种格式保留原始查询,响应被重新表述为支持搜索和检索的多级键值对。另一种格式涉及在原始查询中附加参考资料,同时保持原始响应。
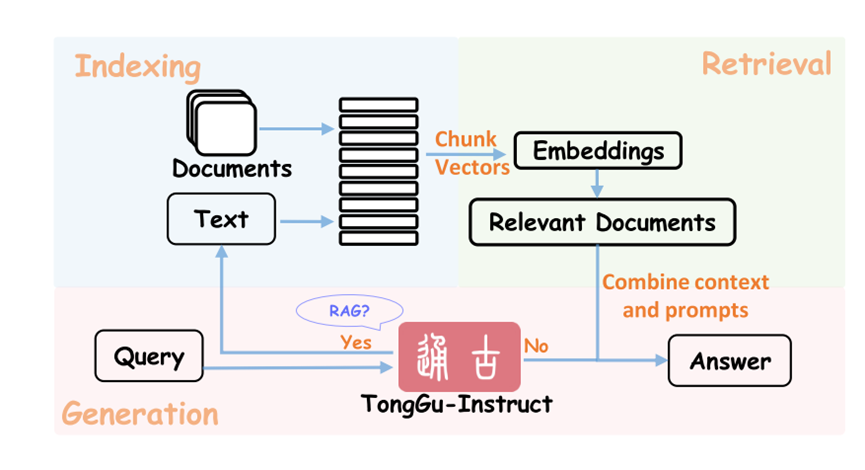
当TongGu接收到用户查询时,如果是知识密集型任务,且缺乏足够的相关知识,则生成多级键值对调用检索模块。然后,检索到的内容被连接成第二指令格式,并重新输入到TongGu中,使其能够输出更准确的答案。这个判断过程是由TongGu自己完成的。最终,这些重新格式化的样本被用来取代ACCN-INS中的原始样本,从而产生增强的检索增强指令微调数据库。值得注意的是,为冗长的句子生成完整的键值对可能很耗时。因此,对模型进行了微调,使其只专注于生成键值对的开始和结束片段,使用省略号来替换过长的中间文本片段。上下文中的完整文本用于基于由模型生成的不完整文本片段的检索。这种方法简单而有效,大大减少了从用户输入到模型响应所需的时间。