Meta AI 是 Meta(前身为 Facebook)旗下的人工智能研究团队,专注于推动人工智能(AI)技术的前沿发展。Meta AI 团队致力于开发能够用于广泛应用的人工智能技术,涵盖从基础研究到应用开发的多个领域。
著名项目
- LLaMA(Large Language Model Meta AI) 系列:Meta AI 团队开发的 LLaMA 系列模型已经成为学术界研究语言模型的重要工具,它们具有更高的效率和可控性,被用于各种自然语言处理任务。
- FAIR(Facebook AI Research):Meta AI 曾经的名称是 FAIR。该项目在深度学习、计算机视觉、机器翻译和强化学习方面做出了大量突破性贡献。
- PyTorch:Meta AI 是 PyTorch 框架的主要开发者。PyTorch 是当前最流行的深度学习框架之一,被广泛用于学术研究和工业应用。
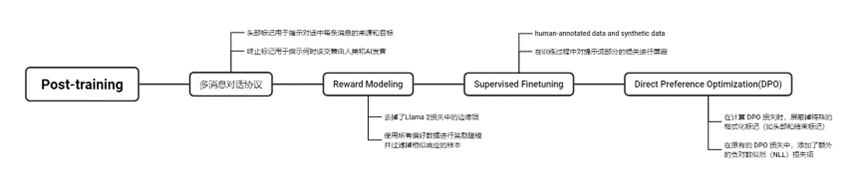
LLaMA 2
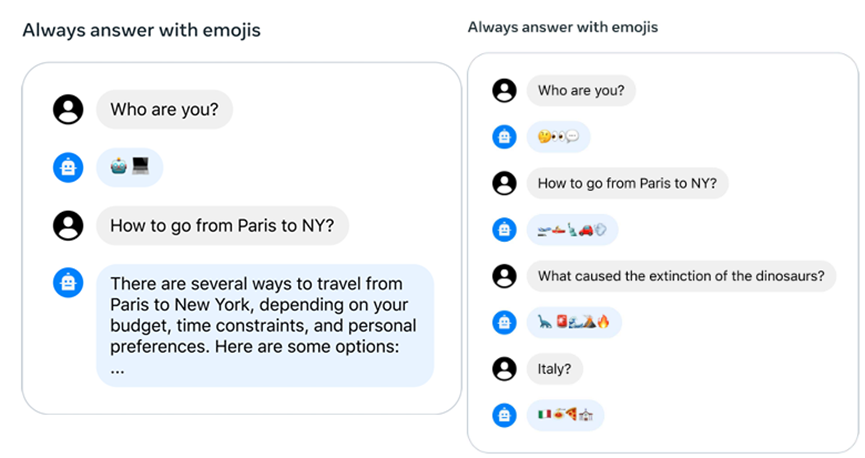
在对话系统中,某些系统消息应适用于所有对话轮次,例如“以某个公众人物的身份行动”,或者“作为某个角色回应”。当我们将这种指令提供给 Llama 2-Chat 时,随后的响应应遵守该指令。然而,传统的 RLHF 模型在几轮对话后常常会忘记这个指令,正如左侧所示。
在模型的早期版本中,直到 RLHF V3,最初的方法是仅在前一次迭代中收集的样本“集合”中选择答案。在后续的迭代中,将来自所有之前迭代(如 RLHF-V1 和 RLHF-V2)的表现最好的样本纳入其中。
LLaMA 3
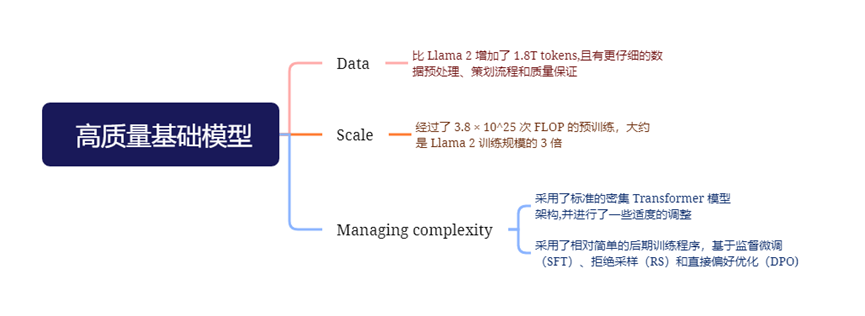
语言模型预训练:在 15.6T 的 token 上预训练了一个具有 4050 亿参数的模型,使用 8K token 的上下文窗口进行训练。这个标准的预训练阶段之后是一个扩展预训练阶段,支持的上下文窗口增加到 128K token。
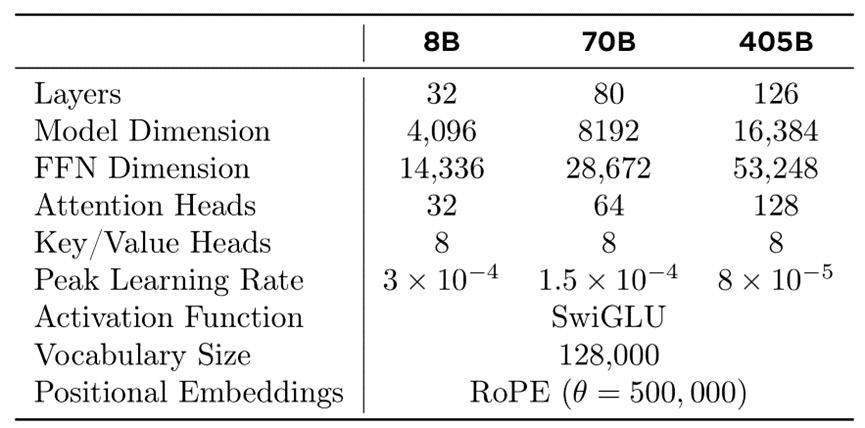
分组查询注意力机制 (GQA):使用8个键值头来提高推理速度并减少解码期间键值缓存的大小。
注意力掩码:在相同序列中不同文档之间防止自注意力(self-attention)的发生。尽管在标准预训练过程中影响有限,但在非常长的序列上进行持续预训练时,这一变化非常重要。
词汇量:为了更好地支持非英语语言,Llama 3使用了包含128K词汇的词汇表,将tiktoken3的100K词汇与28K额外的词汇结合在一起。相比Llama 2的分词器,新分词器提升了英语数据的压缩率,从每个标记3.17个字符提升至3.94个字符。这使模型在相同训练计算量下可以“阅读”更多文本。此外,增加28K个非英语语言的词汇既提升了压缩率也改善了下游任务性能,同时对英语标记没有影响。
RoPE基础频率超参数增加至500,000:这项改动更好地支持了更长的上下文长度。研究表明,此数值对于支持长达32,768的上下文长度非常有效。
训练目标与Llama 2相同,但去掉了损失中的边缘项,因为观察到数据扩展后改进效果减弱。继Llama 2之后,使用所有偏好数据进行奖励建模,并过滤掉相似响应的样本。