
挂载数据云盘、创建训练环境
在webssh端输入lsblk
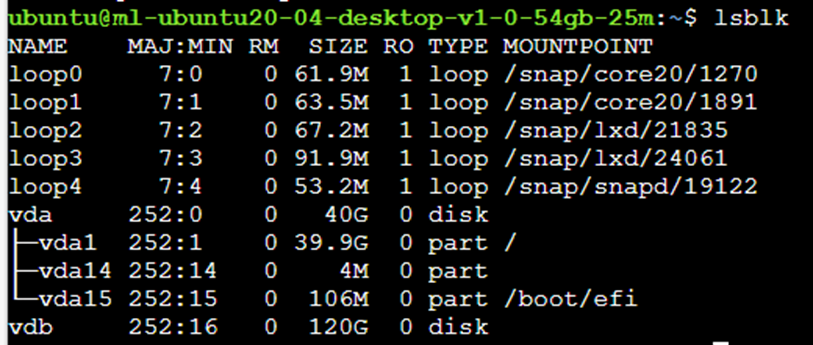
可以看到vdb是我们的数据云盘,没有分区,disk后面没有地址说明还没有链接挂载点
输入sudo fdisk /dev/vdb创建分区
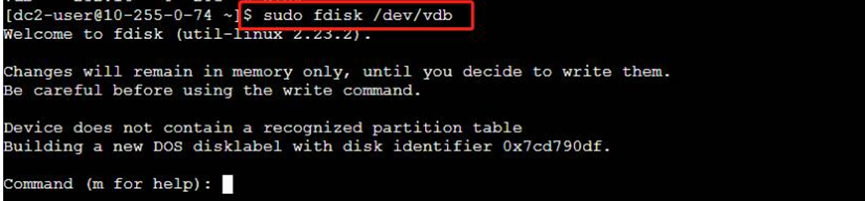
输入n,并按回车,创建新分区。

配置分区号,输入p,并按回车(只要创建4个以下的分区,就选p),然后选择创建的分区号,因为是创建第一个分区,所以用默认值就行,直接按回车,显示如下:

分区表写入磁盘,输入wq,把分区表写入磁盘,并退出

如果需要格式化创建之后的分区,输入sudo mkfs.ext4 /dev/vdb1
由于我自己的需要,所以我这里没有选择创建分区,我直接格式化了整个磁盘,也就是数据云盘, sudo mkfs.ext4 /dev/vdb (ext4是一种文件系统)
创建磁盘挂载的目录,假设挂载到 /mnt/data 目录下,输入sudo mkdir /mnt/data

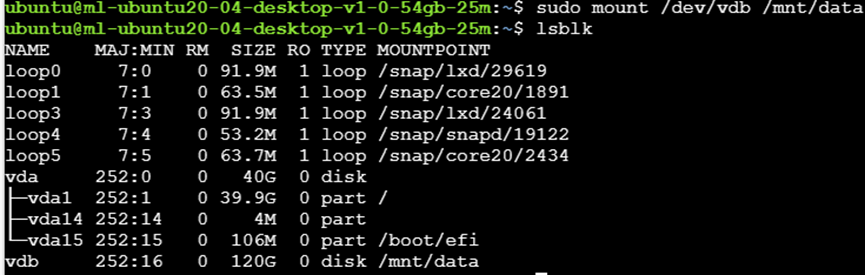
挂载新分区: 然后使用挂载命令 sudo mount /dev/vdb /mnt/data 将新创建的分区挂载到 /mnt/data,可以看到disk后面已经有了挂载的目录
为了确保在重启后挂载仍然有效,可以编辑 /etc/fstab 文件,将新分区的挂载信息加入其中。输入sudo nano /etc/fstab
在文件中输入/dev/vdb /mnt/data ext4 defaults 0 2
按键Crtl+x后,输入y,回车确认,就保存文件退出了
我们现在使用winscp上传文件到数据云盘中,也就是到刚才挂载的目录,会发现没有写入权限
假设我们当前的用户是ubuntu(不同的操作系统用户名不同)就输入
sudo chown ubuntu:ubuntu /mnt/data
这会使 /mnt/data 目录对用户ubuntu可读、可写、可执行。
创建模型训练环境
这里的操作基本上和windows主机相同
首先输入 conda create –name train python=3.10 (现在许多包都要python3.9以上的版本,不然会报错)
激活环境 conda activate train (如果失败的话重启一下服务器)

现在我们要下载对应版本的pytorch和cuda版本以及一些有对应版本需求的包,可以如下网址查看
https://pytorch.org/get-started/previous-versions
我这里选用了pytorch 2.0.1以及对应的cuda版本

接下来安装需要代码需要的包,比如说transformers,pandas,datasets等
完成之后进入数据云盘运行代码,也可以将需要的文件cp到系统盘,不过系统盘一般比较小,如果训练的模型较大,需要提前扩容(有的服务器不让扩容)以免报错,所以我还是建议在数据云盘上进行文件操作,另外数据云盘随时可以扩容,操作起来更加方便。
cd /mnt/data
单卡 python 文件.py
单机多卡 torchrun –nproc_per_node=2 –nnodes=1 文件.py
nproc_per_node是gpu的数量,nnodes是主机的数量