
大语言模型中的强化学习则有很大不同。大语言模型不是从有限的行动集中选择,而是从庞大的词汇表中选择标记,并且它们不断演化的状态由不断增长的文本序列组成。然而,尽管大语言模型能力出色,但在处理长文本序列时,它们仍难以保持连贯性和上下文相关性。要解决这些局限性,需要采用结构化的序列生成方法,而这与强化学习(RL)自然契合。
在现代大语言模型中所观察到的思维链推理,很自然地可以被构建为一个强化学习问题。从这个角度来看,每一个中间推理步骤都被视作是有助于得出最终答案的一个动作。其策略梯度更新公式如下:
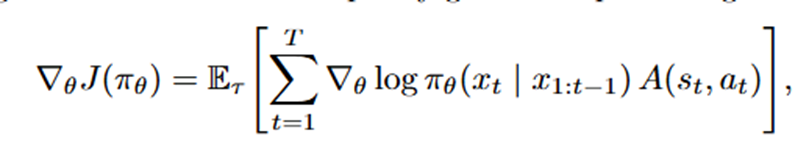
1、Policy Gradient (REINFORCE) 2、SCST 3、Minimum Risk Training (MRT)
4、Advantage Actor-Critic (A2C/A3C)
- 演员(Actor):是一个策略函数,它根据当前状态s来选择动作a。可以将其看作是智能体的决策部分,它决定在当前情况下采取什么行动。例如在一个机器人控制任务中,演员根据机器人当前的位置、速度等状态信息,决定下一步的操作指令。
- 评论家(Critic):是一个值函数V(s),用于评估在某个状态s下的预期回报。它起到了评估员的作用,告诉演员当前状态的好坏程度。比如在一个金融投资任务中,评论家根据当前的市场状态,评估采取某种投资策略可能获得的预期收益。
将强化学习集成到大语言模型推理中通常遵循三个核心步骤:
- 监督微调(SFT):从一个预训练语言模型开始,随后在由高质量人工编写示例组成的监督数据集上进行优化。这一阶段确保模型在格式和风格准则上达到基本的合规性。
- 奖励模型(RM)训练:收集微调模型生成的输出,并由人工进行偏好标注。然后训练奖励模型,以复制这些基于标注的分数或排名,从而有效地学习一个将响应文本映射到标量值的连续奖励函数。
- 强化学习微调:最后,通过策略梯度算法(如近端策略优化算法 PPO)对主语言模型进行优化,以最大化奖励模型的输出。通过不断迭代这个循环,大语言模型学会生成在准确性、实用性和风格连贯性等关键维度上符合人类偏好的响应。
3.1.1 显式奖励建模
显式奖励建模直接根据预定义的规则、启发式方法或人类注释来定义奖励函数。这种奖励结构涉及来自人类或经过训练以近似人类判断(例如排名或成对比较)的专门 AI 模块的直接数字信号。该方法可以产生精确的奖励估计,但在大规模应用时可能耗时或成本高昂。具有代表性的用例包括 “红队” 演习,即专家对有害输出的严重程度进行评级;或者在特定领域的任务中,正确性必须由领域专家进行验证。
3.1.2 隐式奖励建模
隐式奖励建模从观察到的行为、交互或偏好信号中间接推断奖励,通常利用机器学习技术来揭示潜在的奖励结构。它从用户交互指标(如点赞数、接受率、点击模式或会话参与时间)中获取信号。虽然这种方法可以以最小的开销积累大量数据集,但它存在鼓励一些行为的风险,这些行为利用参与度启发式方法,却牺牲了内容质量或准确性。
3.1.3 结果奖励建模
衡量最终结果(例如,最终答案在事实上是否正确,或是否解决了用户的查询)。这个模型易于实现,但对于结论是如何得出的可能提供有限的见解。它在短响应任务中很普遍,在这些任务中,用户主要关注最终陈述的正确性或简洁性。对于长响应任务,基于结果的奖励可能会导致奖励分配问题,即哪些特定的行动或状态导致了特定的奖励结果。
3.1.4 过程奖励建模
在中间推理步骤分配反馈,激励连贯、逻辑一致且结构良好的思维链。这种方法对于涉及数学推导、法律论证或代码调试的任务特别有价值,在这些任务中,得出答案的过程与最终陈述同样重要。在这类问题中,在各个步骤分配的奖励鼓励推理的透明度和稳健的逐步推理。然而,它需要更复杂的注释过程,例如,需要 “黄金标准” 的推理步骤或部分得分。过程奖励可以与结果奖励相结合,以提供强大的多阶段训练信号。
过程奖励建模结合最后一步聚合优于结果奖励建模。
3.1.5 带有自适应奖励模型的迭代强化学习
自适应奖励模型是一种训练方法,旨在通过迭代优化奖励模型和策略模型,持续提高大语言模型的性能。这种方法解决了奖励作弊和奖励模型漂移的问题,这些问题可能在大规模强化学习训练期间出现,当奖励模型与期望目标不一致时就会发生。强化学习过程分为多个迭代,模型在循环中进行训练。每次迭代后,奖励模型会根据最新的模型行为和人类反馈进行更新。奖励模型不是静态的,而是随着时间演变,以更好地与人类偏好和任务要求保持一致。这种适应性确保了随着模型的改进,奖励信号仍然准确且相关。重复迭代过程,直到模型的性能达到稳定或满足期望的基准。奖励模型和策略模型共同进化,每次迭代都使它们更接近最优对齐。
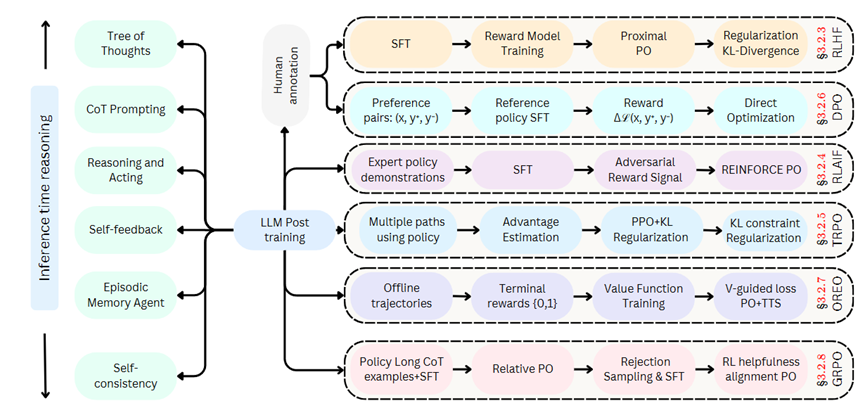
- RLHF(基于人类反馈的强化学习)流程:
- 从 “Human annotation” 开始,经过监督微调(SFT),接着训练奖励模型(Reward Model Training),再使用近端策略优化(Proximal PO),最后进行 KL 散度正则化(Regularization KL – Divergence)。
- DPO(直接偏好优化)流程:
- 先获取偏好对(Preference pairs: (x, y*, y -)),然后基于参考策略进行监督微调(Reference policy SFT),计算损失差(Δℒ(x, y*, y -)),最后进行直接优化(Direct Optimization)。
- RLAIF(某种基于人类反馈的强化学习变体)流程:
- 以专家策略演示(Expert policy demonstrations)为起点,进行监督微调(SFT),接着获取对抗奖励信号(Adversarial Reward Signal),最后使用强化策略优化(REINFORCE PO)。
- TRPO(信任区域策略优化)流程:
- 利用策略生成多条路径(Multiple paths using policy),进行优势估计(Advantage Estimation),采用近端策略优化并结合 KL 正则化(PPO + KL Regularization),最后施加 KL 约束正则化(KL constraint Regularization)。
- OREO(具体含义文中未详述)流程:
- 从离线轨迹(Offline trajectories)开始,设定终端奖励(Terminal rewards {0,1}),进行值函数训练(Value Function Training),最后使用值引导损失和策略优化结合时间跨度平滑(V – guided loss PO+TTS)。
- GRPO(群体相对策略优化)流程:
- 以策略长思维链示例和监督微调(Policy Long CoT examples + SFT)为开端,进行相对策略优化(Relative PO),接着进行拒绝采样和监督微调(Rejection Sampling & SFT),最后进行强化学习有用性对齐策略优化(RL helpfulness alignment PO) 。